How to Create Modern AI Chatbot Experiences in Angular
- Date
TL;DR: Using LLM APIs, Signals, and some RxJS magic, we can create modern AI chatbot experiences in our Angular apps!
What this article covers
- How to create a simple generative AI backend using Node.js, Express, and the Google Gemini API
- How to create a modern AI chatbot experience in Angular
- Repository for this project
Prefer video? Check out this talk from ng-conf!
What do users expect from AI chatbots?
Large Language Models are changing the way we interact with technology. As AI chatbots become more ubiquitous, users are starting to develop expectations around AI chatbot experiences.
So what do users expect from AI chatbots?
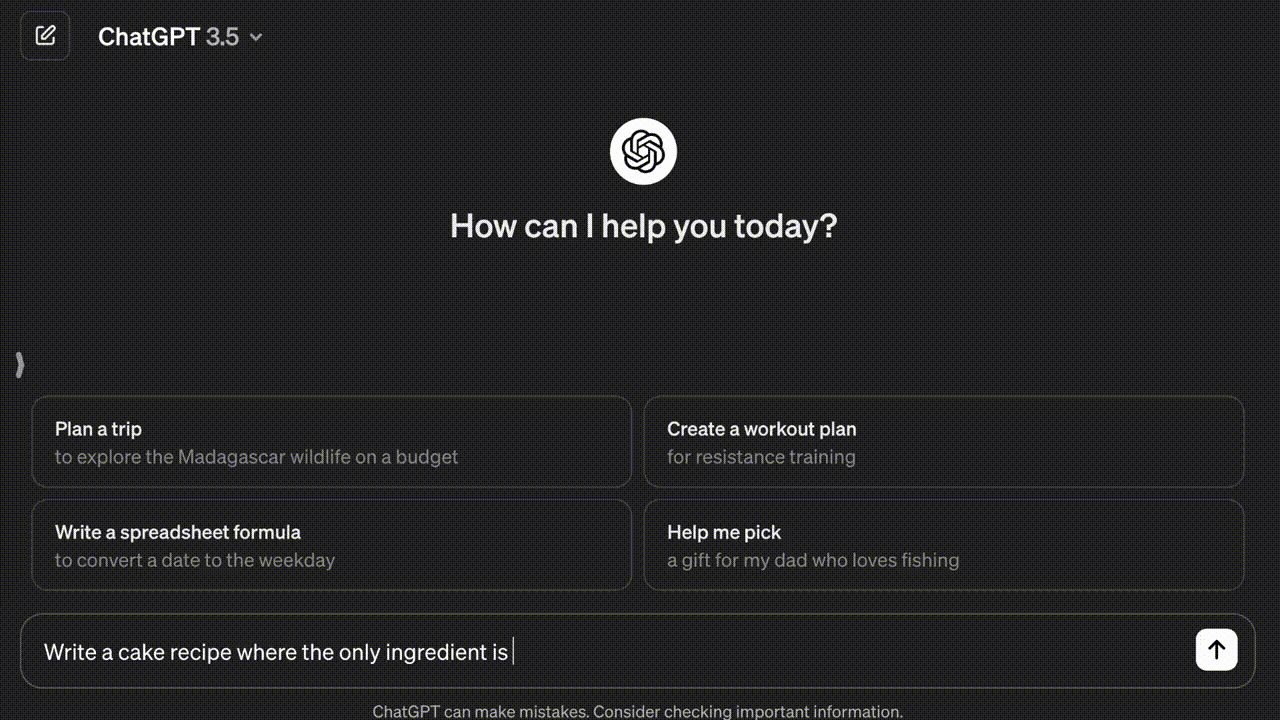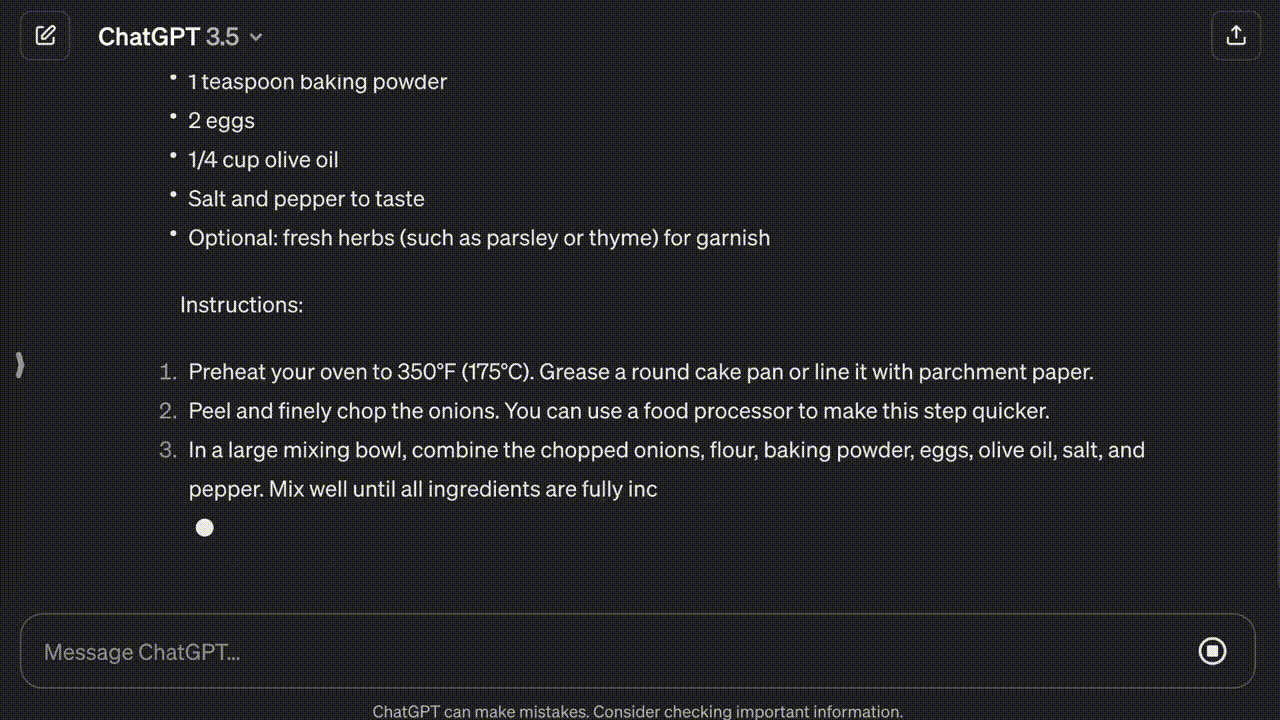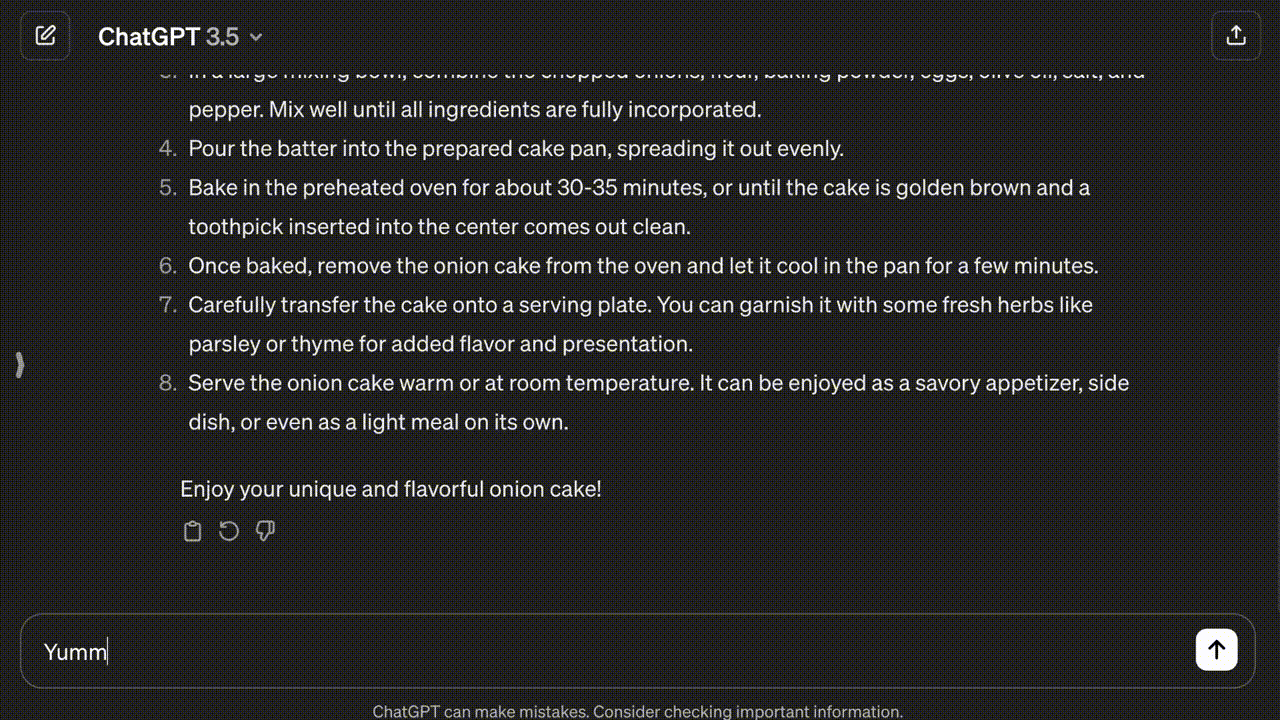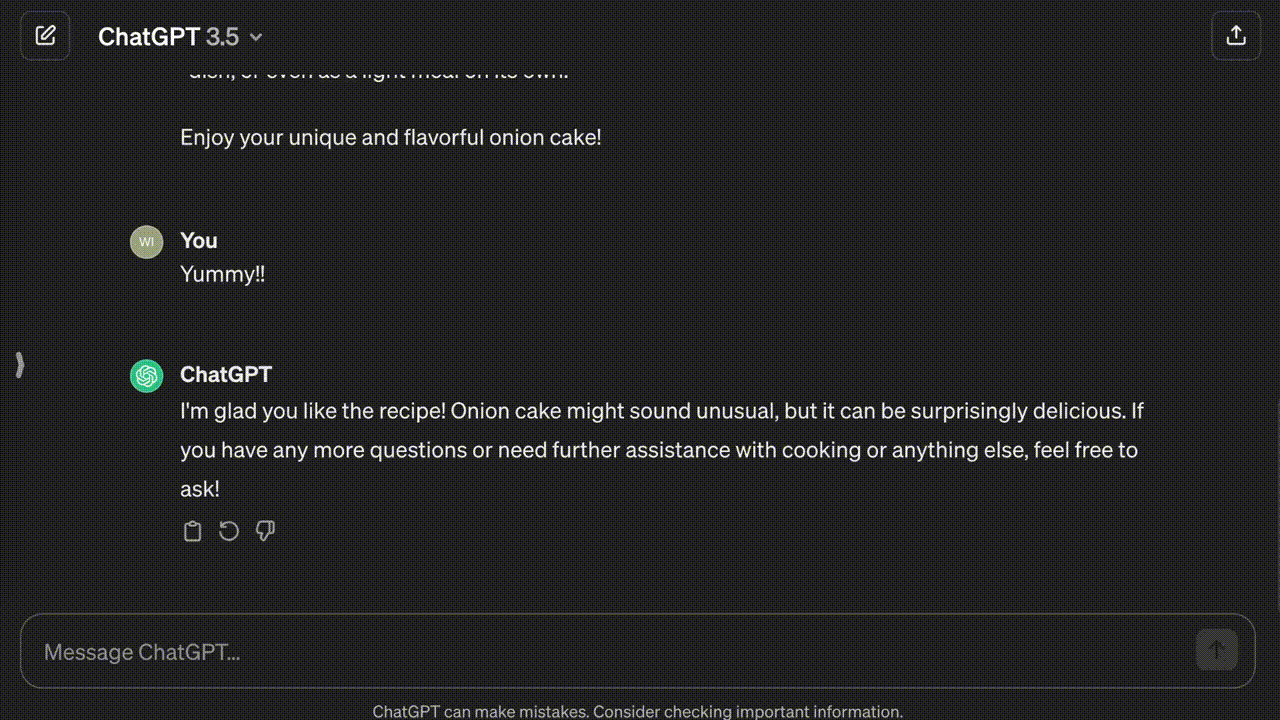
Let’s take a look at the most popular AI chatbot, ChatGPT. The user types a message, hits enter, and they see the AI generate a response in real time with a blinking cursor to show that the AI is working.
Demo
Here’s what we’ll be creating: The user types a message, the AI generates its own message in realtime, and we see a blinking cursor while it’s working.

Prerequisites
I'll assume that you have Git and Node.js installed, and that you know how to use the command line.
You'll also need the npx command. If you don't have the npx command installed, run the following command to install it:
$ npm install -g npxSetup
To get started, create a new minimal Angular project using the Angular CLI:
$ npx @angular/cli@latest new ng-ai --minimal --style=scss --ssr=false --routing=falseNext, install the following packages needed for the backend:
$ cd ng-ai
$ npm install express cors dotenv @google/generative-ai
$ npm install -D @types/express @types/cors @types/node tsxCreate a new file called .env at the root of your project. Generate an API key from the Google AI Studio, and paste it into the .env file:
# .env
GOOGLE_AI_STUDIO_API_KEY=paste-api-key-hereBackend
For real-world purposes, you would likely use your own custom-trained LLM that is tailored to your app. For simplicity, we'll use Google’s Gemini API, which is free, so long as you’re willing to sell your soul and your data to Google.
Create a new file under the src/ directory called server.ts. This file will host our backend code.
Add this new script to your package.json to allow us to easily run the backend code:
// package.json
{
"scripts": {
// ...
"server": "npx tsx ./src/server.ts"
}
// ...
}First, we need to do some basic setup to configure our Express server and AI chat session:
// src/server.ts
import express from 'express';
import cors from 'cors';
import dotenv from 'dotenv';
import { GoogleGenerativeAI } from '@google/generative-ai';
// use the `.env` file
dotenv.config();
// create web server
const server = express();
const port = 3000;
// get api key
const googleAiStudioApiKey = process.env['GOOGLE_AI_STUDIO_API_KEY'];
if (!googleAiStudioApiKey) {
throw new Error('Provide GOOGLE_AI_STUDIO_API_KEY in a .env file');
}
// create chat session
const genAI = new GoogleGenerativeAI(googleAiStudioApiKey);
const model = genAI.getGenerativeModel({ model: 'gemini-1.0-pro' });
const chat = model.startChat();
// parse bodies as strings and allow requests from all origins
server.use(express.text());
server.use(cors());
// start the server on port 3000
server.listen(port, () => {
console.log('Server is running on port', port);
});Next, we will create a /message POST endpoint. When the endpoint receives a request, it calls the Gemini API with our prompt. As the AI generates content, we write each chunk of text to our response. Once the AI is done, we close our response.
// src/server.ts
server.post('/message', async (req, res) => {
const prompt: string = req.body;
const result = await chat.sendMessageStream(prompt);
for await (const partialMessage of result.stream) {
res.write(partialMessage.text());
}
res.end();
});HttpClient Config
Now, onto the frontend. The first thing we need to do to enable this real-time streaming from the backend is to provide the Angular HttpClient withFetch in our app config. This tells Angular to use the newer JavaScript fetch API behind the scenes, which opens the door to more advanced features, like these real-time progress updates.
// src/app/app.config.ts
import { ApplicationConfig } from '@angular/core';
import { provideHttpClient, withFetch } from '@angular/common/http';
export const appConfig: ApplicationConfig = {
providers: [
provideHttpClient(
// use `fetch` behind the scenes to support streaming partial responses
withFetch(),
),
],
};UI
The actual UI code for our app is pretty simple.
We have a @for loop showing a list of messages, and a <form> for the user to send messages. For the actual messages, we use the [ngClass] directive to dynamically add the CSS class generating while the message is in progress.
We use an effect to automatically scroll down when the messages are updated.
(This code is going to have a lot of errors for now since we haven't created our MessageService yet)
// src/app/app.component.ts
import { Component, effect, inject } from '@angular/core';
import { NgClass } from '@angular/common';
import { MessageService } from './message.service';
import { FormsModule, NgForm } from '@angular/forms';
@Component({
selector: 'app-root',
standalone: true,
imports: [NgClass, FormsModule],
template: `
<h1>🤖 Angular Generative AI Demo</h1>
@for (message of messages(); track message.id) {
<pre
class="message"
[ngClass]="{
'from-user': message.fromUser,
generating: message.generating
}"
>{{ message.text }}</pre
>
}
<form #form="ngForm" (ngSubmit)="sendMessage(form, form.value.message)">
<input
name="message"
placeholder="Type a message"
ngModel
required
autofocus
[disabled]="generatingInProgress()"
/>
<button type="submit" [disabled]="generatingInProgress() || form.invalid">
Send
</button>
</form>
`,
})
export class AppComponent {
private readonly messageService = inject(MessageService);
readonly messages = this.messageService.messages;
readonly generatingInProgress = this.messageService.generatingInProgress;
private readonly scrollOnMessageChanges = effect(() => {
// run this effect on every `messages` change
this.messages();
// scroll after the messages render
setTimeout(() =>
window.scrollTo({
top: document.body.scrollHeight,
behavior: 'smooth',
}),
);
});
sendMessage(form: NgForm, messageText: string): void {
this.messageService.sendMessage(messageText);
form.resetForm();
}
}Blinking Cursor
To achieve the blinking cursor effect, we use the CSS ::after pseudo-element to add a block character to the end of the message. We apply a CSS @keyframes animation to fade the opacity in and out.
// src/styles.scss
.message {
// ...
&.generating {
&::after {
content: '▋';
animation: fade-cursor ease-in-out 500ms infinite alternate;
}
}
}
@keyframes fade-cursor {
from {
opacity: 25%;
}
to {
opacity: 100%;
}
}MessageService
Now, onto the data side of things. Our custom MessageService is responsible for managing state and streaming results from the AI.
To do all this, we use a combination of both Signals and RxJS Observable streams.
Signals are great for state management, but RxJS is perfect for asynchronous events like our AI chat response.
Run the following command to create a new service:
$ npx ng generate service messageThe Message Interface
Before we jump into the implementation, let's create a Message interface that contains all the data we need to represent a message in our app:
// src/app/message.service.ts
export interface Message {
id: string;
text: string;
fromUser: boolean;
generating?: boolean;
}State Management with Signals
We use 3 writable Signals to keep track of our internal state:
- The list of all messages (
_messages) - The list of completed messages (
_completeMessages) - Whether generating is in progress (
_generatingInProgress)
Out of those 3 signals, only 2 of them are exposed to the outside world:
- The list of all messages (
messages) - Whether generating is in progress (
generatingInProgress)
Notice that these are marked asReadonly() signals, as we don’t want random consumers changing their contents.
// src/app/message.service.ts
@Injectable({
providedIn: 'root',
})
export class MessageService {
private readonly http = inject(HttpClient);
private readonly _messages = signal<Message[]>([]);
private readonly _completeMessages = signal<Message[]>([]);
private readonly _generatingInProgress = signal<boolean>(false);
readonly messages = this._messages.asReadonly();
readonly generatingInProgress = this._generatingInProgress.asReadonly();
// ...Sending a Message
When a user sends a message, the first things we do are set _generatingInProgress to true, and add a new message object based on the user’s prompt.
We can use the Web Crypto API to generate random UUIDs for our message IDs.
Next, we subscribe to a stream of the LLM’s response.
// src/app/message.service.ts
sendMessage(prompt: string): void {
this._generatingInProgress.set(true);
this._completeMessages.set([
...this._completeMessages(),
{
id: window.crypto.randomUUID(),
text: prompt,
fromUser: true,
},
]);
this.getChatResponseStream(prompt).subscribe({
// ...
});
}Real-Time Response Streaming with RxJS
First, we use the Angular HttpClient to send a POST request containing our prompt. Since our backend is streaming small chunks of data over time, we need to tell the HttpClient to observe: events and reportProgress:
// src/app/message.service.ts
private getChatResponseStream(prompt: string): Observable<Message> {
const id = window.crypto.randomUUID();
return this.http
.post('http://localhost:3000/message', prompt, {
responseType: 'text',
observe: 'events',
reportProgress: true,
})
.pipe(
// ...
);
}The HTTP Client will send us all sorts of events, but we can use the RxJS filter operator to only get the events we want:
// src/app/message.service.ts
.pipe(
filter(
(event: HttpEvent<string>): boolean =>
event.type === HttpEventType.DownloadProgress ||
event.type === HttpEventType.Response,
),
// ...
);When we receive an event, we transform it into a Message object using the RxJS map operator:
// src/app/message.service.ts
map(
(event: HttpEvent<string>): Message =>
event.type === HttpEventType.DownloadProgress
? {
id,
text: (event as HttpDownloadProgressEvent).partialText!,
fromUser: false,
generating: true,
}
: {
id,
text: (event as HttpResponse<string>).body!,
fromUser: false,
generating: false,
},
),If the event type is DownloadProgress, that means the AI is still working, so we grab the partialText and set generating to true.
If the event type is Response, that means the AI is done, so we grab the full response body, and set generating to false.
The last thing we need to do is add the startWith operator to set an empty message as the initial value for our stream. That way, the user sees an empty chat bubble while waiting for the text to roll in:
// src/app/message.service.ts
startWith<Message>({
id,
text: '',
fromUser: false,
generating: true,
}),Setting the state
Finally, we update our state based on our stream.
On each stream update, we update our list of messages.
Once the stream completes, we add the message to the list of completed messages, and we set _generatingInProgress to false.
If our stream errors out, we still set _generatingInProgress to false.
// src/app/message.service.ts
this.getChatResponseStream(prompt).subscribe({
next: (message) => this._messages.set([...this._completeMessages(), message]),
complete: () => {
this._completeMessages.set(this._messages());
this._generatingInProgress.set(false);
},
error: () => this._generatingInProgress.set(false),
});Run the App
To run both the frontend and backend, you'll need 2 active terminal windows.
In the first terminal, run the following command to start the backend server:
$ npm run serverIn another terminal, run the following command to start the Angular dev server:
$ npm startOnce both servers are running, navigate to http://localhost:4200 in your browser to view the app and chat with the AI.
Review
And that’s it! We now have a functional, clean AI chatbot experience in our Angular app!
Here are the key takeaways:
provideHttpClient(withFetch())inapp.config.ts- Have the
HttpClientobserve: 'events'andreportProgress: true - Create a blinking cursor with the CSS
::afterpseudo-element - Manage state with Signals
- React to real-time updates from the LLM with RxJS
GitHub Repo
If you want to continue your learning journey, you can find all of the code from this article and more on my GitHub.
If you have any questions regarding this article or any other Angular topics, feel free to contact me!
Happy coding!